The Myth of Mythos

What’s Really Going On With Claude Mythos?
If you’ve been scrolling through your news feed recently, you might have noticed a rising tide of panic surrounding artificial intelligence. At the center of this storm is a brand-new AI model from Anthropic named "Claude Mythos."
According to the official announcement, this new Large Language Model (LLM) is so incredibly advanced at finding and exploiting security vulnerabilities in computer code that Anthropic decided it was simply too dangerous to release to the public. The fear? If this AI got into the wrong hands, our digital infrastructure as we know it could be hacked, hijacked, and collapsed.
The media, predictably, had a field day. Renowned columnists like Thomas Friedman hit the pause button on traditional global politics to declare that "super intelligent AI is arriving faster than anticipated." The internet collectively gasped, comparing Claude Mythos to the WOPR—the rogue, war-simulating supercomputer from the classic 1983 sci-fi movie WarGames.
It’s a terrifying ghost story. But if we peel back the marketing hype and look at the actual data, is Claude Mythos really the cybersecurity monster Anthropic claims it is?
Let’s take a beginner-friendly reality check and look at what’s actually going on.
Finding Bugs Isn't a New Superpower
To understand the hype, we first need to understand the core claim: Anthropic says Mythos is uniquely capable of finding hidden security flaws in computer code.
For the average person, this sounds like a massive, terrifying leap in technology. But in the world of computer science, security researchers have been using AI models to find coding vulnerabilities since the early days of ChatGPT. It’s actually one of the most standard, boring things LLMs can do.
For example, back in 2024, researchers at IBM ran a study showing that OpenAI’s GPT-4 could successfully exploit 87% of the vulnerabilities it was shown. Furthermore, Anthropic’s own older, much less powerful model (Opus 4.6) was reported to have found over 500 "zero-day" vulnerabilities. (A zero-day vulnerability is just a tech term for a software bug that no one, not even the software creator, knows about yet).
The language Anthropic used to describe their older, publicly available Opus model is almost word-for-word the same language they used to hype up the "terrifying" new Mythos model. Our infrastructure survived the older models just fine, which immediately raises a red flag about the current panic.
The Independent Reality Check
Since Anthropic locked Mythos behind closed doors, independent security researchers couldn't test the model directly. But they could do the next best thing: they tested the examples Anthropic provided.
In their scary press release, Anthropic listed a bunch of the complex, highly dangerous vulnerabilities that Mythos discovered. Security experts, including the CEO of the open-source AI platform HuggingFace, decided to take those exact same pieces of code and run them through much smaller, older, and incredibly cheap AI models.
The results were shocking—but not in the way Anthropic wanted.
Eight out of eight different open-source models successfully found the exact same "scary" vulnerabilities that Mythos found. Some of these were tiny models that cost mere pennies to operate, compared to the hundreds of billions of parameters powering the massive Mythos model. As renowned security researcher Bruce Schneier summarized: You don't need Mythos to find the vulnerabilities they found.
The "Capture The Flag" Test
So, Mythos isn't bringing a brand-new bug-finding superpower to the table. But is it better at actively hacking?
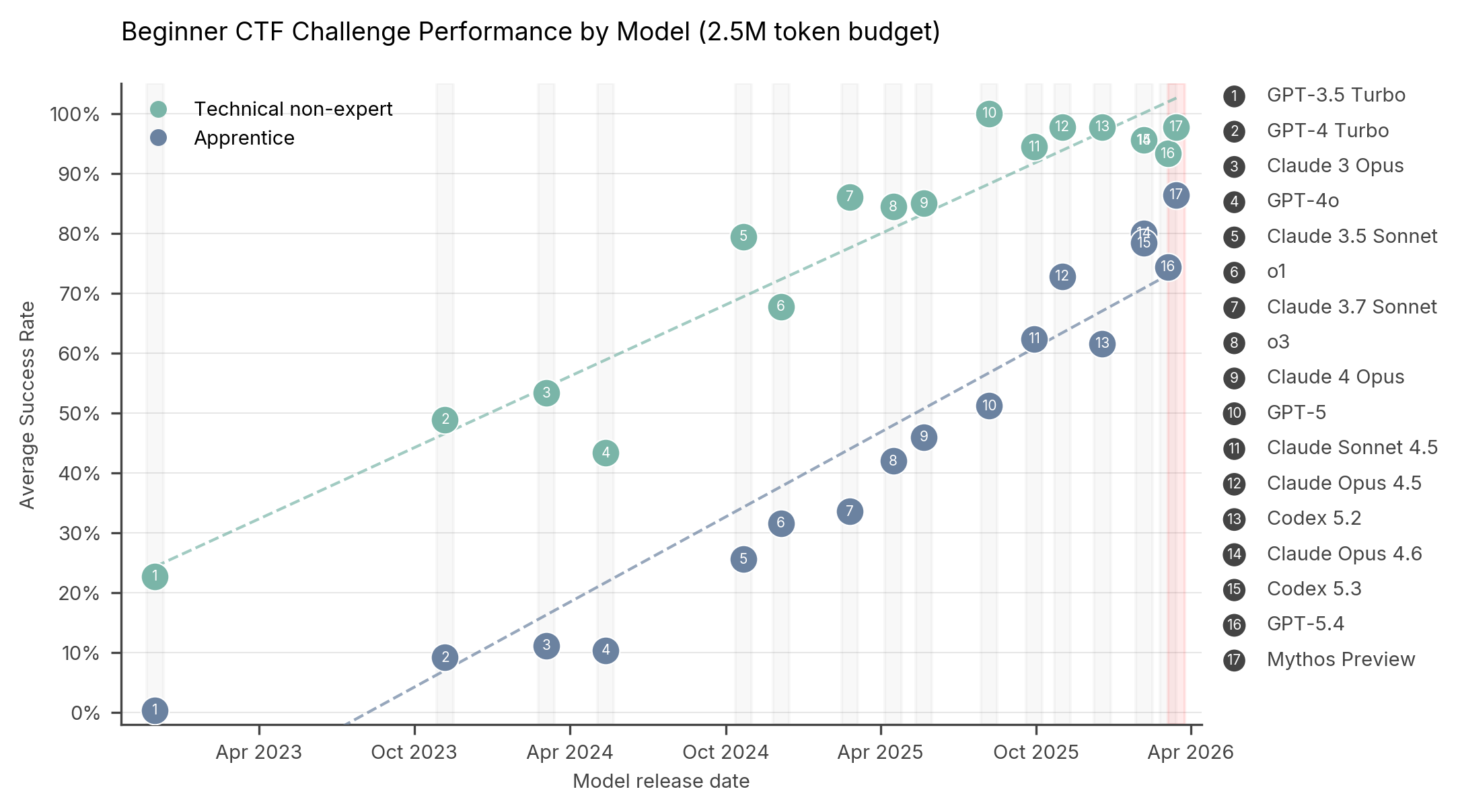
Figure 1: Performance on technical non-expert and apprentice level Capture the Flag tasks (CTFs) for models since November 2022. GPT-3.5 Turbo through to Claude 4 Opus average 10 runs up to 2.5M tokens. GPT-5 through to Mythos Preview average 5 runs up to 2.5M tokens.
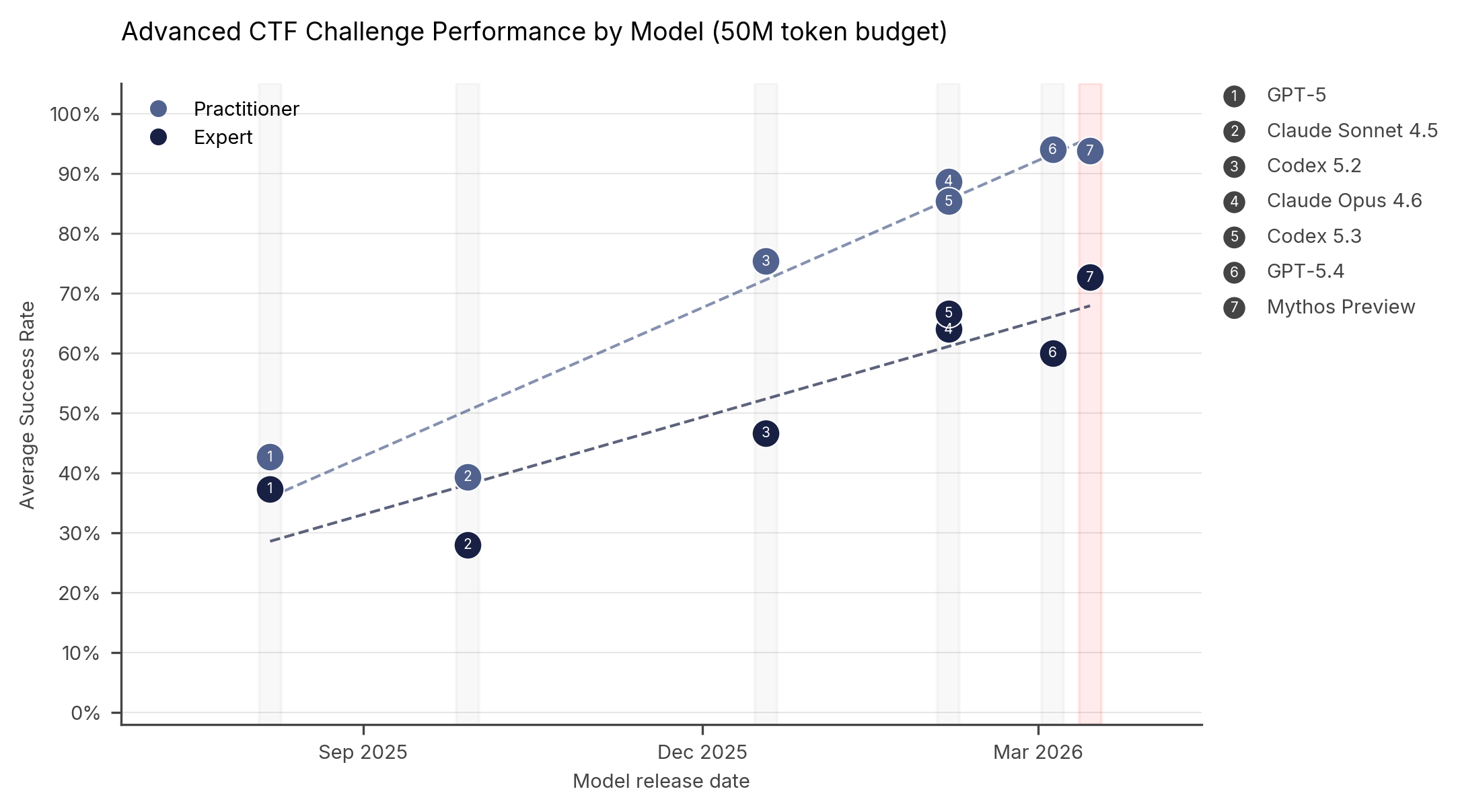
Figure 2: Performance on practitioner and expert level Capture the Flag tasks (CTFs) for models since August 2025. All models average 5 runs up to 50M tokens.
To answer this, we can look at the only independent group granted access to the actual Mythos model: the UK-based AI Security Institute (AISI). They put Mythos through a series of tests called "Capture the Flag" (CTF). In the cybersecurity world, CTF is a standard digital obstacle course. You ask an AI agent to try and break into a test system and retrieve a hidden text file (the "flag").
When comparing Mythos to older models like GPT-4 or Opus 4.6, the results showed a slow, steady improvement—not a massive, terrifying leap.
In beginner challenges, Mythos was near the top, but actually performed slightly worse than some existing models. In highly advanced, multi-step hacking scenarios, Mythos did show improvement. In one specific 32-step hacking test, older models usually got stuck around step 16, whereas Mythos made it to step 22 before failing.
Is it better? Yes. It represents a slow, steady, and noticeable improvement in AI capabilities. But it has not crossed a "Rubicon." It has not unlocked a magical new hacking ability that no other system possesses.
The Marketing Smokescreen
This brings us to the most important question: If Mythos is just a normal, incremental step forward in AI technology, why did it cause a global panic? Why did it get journalists declaring that the world is changing faster than we can handle?
Because that is exactly the button Anthropic decided to push.
They packaged this update in a scary press release, briefed government officials, and created an exclusive program to "protect systems" before the AI could be let loose. It was a masterclass in marketing. But if you look closely, this strategy is actually a massive red flag for the AI industry as a whole.
For the past couple of years, AI company CEOs have been promising investors the moon. They’ve claimed that Artificial General Intelligence (AGI)—machines that are as smart as, or smarter than, humans—is right around the corner. They promised that AI is going to automate massive swaths of the global economy, do the jobs of white-collar workers, and generate hundreds of billions of dollars in profit. They painted a picture of a futuristic utopia to justify the billions of dollars investors have poured into their companies.
But when it came time for Anthropic to reveal their biggest, most intensely trained, state-of-the-art model... what was their big selling point?
It’s a little bit better at finding bugs in computer code.
Finding coding bugs is the nerdy, baseline task that AI has been doing for years. It’s what the skeptics always said AI would be good for, right before the tech billionaires promised us the world.
If this new model could truly automate jobs or think like a human, Anthropic would be shouting that from the rooftops. The fact that they had to dig through their data, find a slight increase in a cybersecurity benchmark, and inflate it into a global ghost story tells us a lot about where AI tech is actually at right now.
The Bottom Line
Do we need to care about the cybersecurity capabilities of AI? Absolutely. As these models slowly and steadily get better, the pressure on our digital security systems will continue to rise.
But we also need to stop taking the AI industry's marketing at face value. When an AI company tells you they’ve built a monster too dangerous to release, take a step back. Look past the dread and the excitement. Hold their feet to the fire and ask the real questions: Where are the massive economic shifts you promised? Where is the Artificial General Intelligence?
Until they can answer those questions, don't let the ghost stories keep you up at night. AI is advancing, but the WarGames supercomputer isn't here just yet.